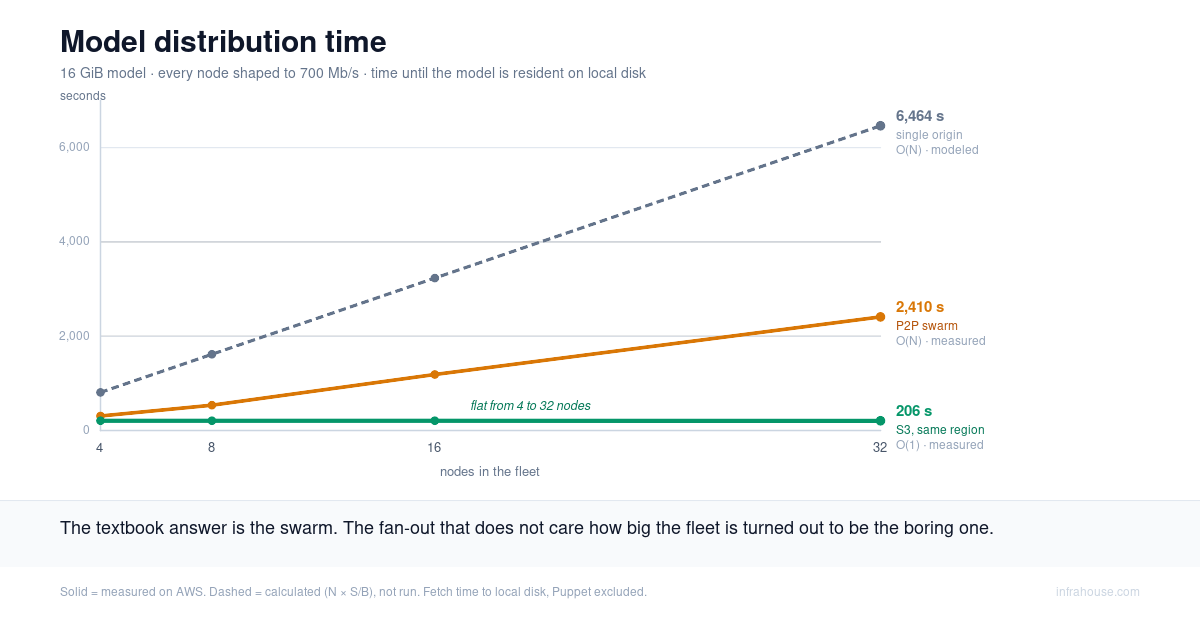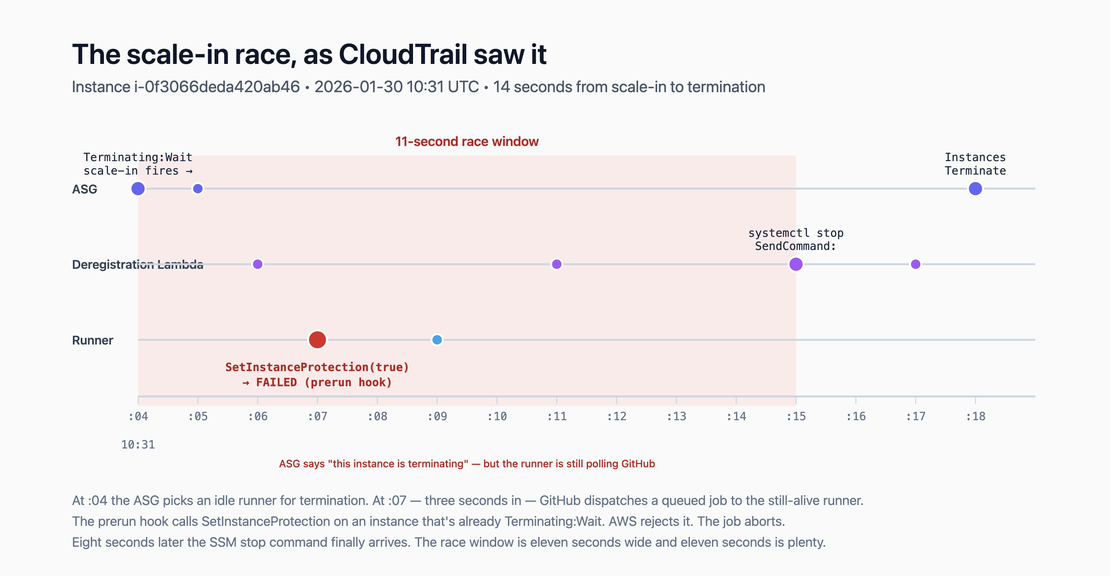
On January 30 this year, I filed an issue against our self-hosted GitHub Actions runner module
infrahouse/terraform-aws-actions-runner.
The title: “Actions runner gets terminated and job fails with SetInstanceProtection error.”
Severity: annoying. Frequency: every couple of days. Workaround: rerun the job, which almost always
succeeded on the second attempt.
The issue sat open for two and a half months. Not because nobody cared — because every time someone hit it, the workaround was so cheap that investigating the root cause was always the wrong choice in the moment. Rerun, move on, context switch back to whatever you were doing. The tax was real, but it was paid in small denominations: fifteen minutes of a senior engineer’s attention, distributed across the organization, a couple of times a week, for months.
Then in early April the startup’s CTO surfaced the same failure in the security channel — frequent enough in vulnerability-check jobs that it was interrupting his work, with the same error in the logs:
An error occurred (ValidationError) when calling the SetInstanceProtection operation:
The instance i-010507d1de5ce4f78 is not in InService or EnteringStandby or Standby.
When the CTO is the one asking, the bug is no longer a paper cut. It became the priority.
This post is the full debugging story — two wrong hypotheses, the audit-logs detour that unblocked the real RCA, the design decision to make the race survivable instead of eliminating it, and the four pull requests across two repositories that closed it out.
What the module does and where it breaks
terraform-aws-actions-runner provisions an AWS Auto Scaling Group of EC2 instances that register
themselves as self-hosted GitHub Actions runners at the organization level. It supports a warm
pool, so idle runners can be hibernated and resumed quickly when demand spikes. It supports
ephemeral credentials via a GitHub App. It handles registration at boot and deregistration at
shutdown. In our CI, a single ASG of ~10 runners has been handling jobs for 100+ repositories for
over a year.
A runner job has two phases of instance-lifecycle management:
- Pre-run hook (
gha_prerun.sh): before the job runs, the script callsSetInstanceProtection(protect=true)on the ASG. This prevents the instance from being scaled in while a job is executing. - Post-run hook (
gha_postrun.sh): after the job finishes, the script callsSetInstanceProtection(protect=false)to release the instance back to the scaling pool.
The bug: occasionally, gha_prerun.sh fails with:
An error occurred (ValidationError) when calling the SetInstanceProtection operation:
The instance i-XXXXXXXXXXXXXXXXX is not in InService or EnteringStandby or Standby.
The job exits with status 1 before any user code runs. The engineer who triggered the workflow reruns it. The second attempt almost always succeeds on a different runner. Life goes on.
The first (wrong) RCA, in two stages
The first theory came from observation. A teammate looked up the failing instance IDs —
i-010507d1de5ce4f78, i-006ef92d47103a813, i-084bce8327f53e488 — and every one returned
InvalidInstanceID.NotFound. The natural conclusion: the runner is somehow producing fake or
stale instance IDs. The Linear ticket title was gha_prerun.sh uses non-existent instance IDs, breaking CI across multiple repos. The hypotheses to investigate included “the hook reads the
instance ID from a file written at instance launch time rather than querying the live EC2
metadata service” and “a GitHub runner registration for a terminated instance somehow still
receives jobs.” The search space was “something is wrong with how the runner determines its
own instance ID.”
That framing is reasonable from the evidence at hand, but it’s also where things go sideways. An instance ID that doesn’t resolve to anything is one of those observations that admits too many explanations — a bug in ID discovery, a race in the runner’s startup, a stale cache, a bug in the metadata service, a terminated instance that aged out. Each of those has a plausible mechanism. Without more data, there’s no way to choose between them.
A few hours later, an AI-assisted RCA produced a specific mechanism:
Warm pool hibernation bypasses the
InServicelifecycle guard instart-actions-runner.sh, causing the runner to accept GitHub jobs while the ASG instance is still inWarmed:Pending:Proceedstate.SetInstanceProtectionthen fails because the API requiresInService,EnteringStandby, orStandby. The lifecycle hook then times out and the instance is abandoned and terminated. By the time we investigated, the instance IDs were gone fromdescribe-instances(terminated instances are only visible for ~1 hour).
This is a careful piece of reasoning. It doesn’t contradict the “non-existent IDs” observation;
it absorbs it. The IDs weren’t fake, the theory goes — they were real at the moment of failure,
their protection calls failed, their lifecycle hooks timed out, and AWS terminated them. An hour
later they aged out of describe-instances. The mechanism is the warm-pool resume race; the
disappearing IDs are a downstream consequence.
The proposed fix was to add the same InService wait that already existed in
start-actions-runner.sh to gha_prerun.sh itself. The writeup was thorough, the code change
small, the reasoning internally consistent.
It was also wrong about the mechanism. And the reason it was wrong is worth dwelling on. The reasoning in the RCA was sound. The data behind it wasn’t enough to support any conclusion at all.
Why I knew it was wrong before I could prove it
The “terminated and aged out” half of the theory is real AWS behavior. Instances do age out of
describe-instances about an hour after termination. That part is correct. The problem is that
it was offered as evidence for a warm-pool-resume race specifically, when in fact it’s consistent
with any mechanism that terminates the instance. Scale-in terminates. Lifecycle-hook timeout
terminates. Manual termination terminates. The disappearing IDs don’t distinguish between them.
Warm-pool transitions leave a specific, recognizable trace in the ASG scaling activity log —
there is a Warmed:Pending:Proceed → InService event when a warm instance is brought online.
Nobody had pulled that log to check. The same May 2025 puppet-code fix for the boot-up
InService guard existed precisely because that kind of race had happened before, and was
visible in the activity log when it did. If the new bug was another instance of that family,
the activity log would show it.
There’s a second reason I was skeptical. The May 2025 fix gated actions-runner.service start
on InService. If the current bug were a warm-pool-resume race, that existing fix would have
caught it — the proposed new fix (the same check in gha_prerun.sh instead of
start-actions-runner.sh) is the same mechanism applied at a different layer. The fact that the
bug was still happening meant either the mental model was wrong, or the existing fix was
broken. Neither of those was checked.
And the mental model is, I think, exactly why the warm-pool hypothesis got reached for. The May 2025 fix made warm-pool-resume races a familiar and well-understood category. The Linear ticket title had already narrowed the search space to “something about the instance ID being wrong.” A warm-pool resume is one plausible way a runner could fail to know its own lifecycle state. The mechanism fit the shape of the search; the search was pointed in the wrong direction.
None of this is a criticism of the AI-assisted RCA. A language model given “here’s an error message, here are some instance IDs that don’t exist, here’s the repo structure” will produce the best-fitting mechanism from the available evidence. If the evidence is ambiguous, the produced mechanism will be ambiguous too — but it will look specific, because language models are good at generating specificity. A correct-sounding wrong answer is the default output when the input is insufficient. The way you catch that is to get more data.
The same session produced a list of suggested workarounds — deregister the runner from the
GitHub org admin UI, terminate the EC2 instance directly, open a PR against github-control to
add a new runner label — all of which required AWS and GitHub permissions that the affected
developers don’t have. Without supporting data about the organization’s permission model, the
advice was technically correct and operationally useless.
In this case, more data meant CloudTrail.
And like every AWS organization set up through Control Tower, ours dutifully collects it and drops it in an S3 bucket in the log-archive account.
Where it sits. Untouched.
The real blocker: audit logs you can’t query
This is the part of the story I want startup CTOs to understand even if they skip the rest.
Control Tower is AWS’s opinionated way to set up a multi-account organization. One of its default features is org-wide CloudTrail aggregation: every API call made in every account in the organization gets logged to a centralized S3 bucket in a dedicated “log-archive” account. This is a genuinely great feature. It’s the backbone of any serious security posture — it’s the same infrastructure that made our ISO 27001 certification tractable. It’s what gives you the evidence for compliance audits. It’s what lets you answer the question “who did what, when?” after an incident.
But it’s only valuable if you can query it.
By default, Control Tower doesn’t set up Athena. The logs are there. The schema is well-known.
The S3 bucket exists. But there’s no query interface. If you want to answer a question like
“show me every failed SetInstanceProtection call in the last 30 days, partitioned by account,”
you need to:
- Create an Athena workgroup in the log-archive account.
- Define the CloudTrail table with the right SerDe and partition schema.
- Configure partition projection so you don’t have to manually add partitions for every day.
- Grant the right cross-account IAM to let you query from your admin account.
- Set up an output S3 bucket for query results.
This is a day of work. Maybe two if you’ve never done it before. None of it is intellectually interesting. All of it is the prerequisite to using a security feature you already paid for.
We hadn’t done it. Nobody had. For two and a half months, I had CloudTrail logs sitting in S3 that would have told me the exact timeline of every failure, and I had no way to ask them questions. The AI-assisted RCA produced a plausible hypothesis because the only data it had was the error message and the instance IDs; it couldn’t falsify its own guess because the data that would falsify it was unreachable.
So I stopped working on the bug and set up Athena.
The Terraform to do this is in the log-archive account. Three pieces: an S3 bucket for query
results (with a 30-day lifecycle rule so it doesn’t grow forever), a dedicated cloudtrail
Athena workgroup, and a Glue catalog database with one table over the CloudTrail bucket. The
interesting part is the table.
Partition projection is what makes this maintainable. CloudTrail writes objects under
AWSLogs/<org-id>/<account-id>/CloudTrail/<region>/<year>/<month>/<day>/ — five levels of
partitioning. Without projection, Athena needs every partition registered in the Glue catalog
before it’ll query anything under it. That means either running MSCK REPAIR TABLE on a
schedule (slow, breaks when new accounts join) or writing Glue crawlers (expensive, redundant).
CloudTrail Lake is another option if you want a managed query surface, but it’s a separate
product with separate ingestion costs, and per-account lookup-events calls scale badly across
a Control Tower org.
Partition projection skips the catalog entirely. You declare the shape of the partition space in table properties and Athena derives partition locations on the fly:
parameters = {
"projection.enabled" = "true"
"projection.account_id.type" = "enum"
"projection.account_id.values" = join(",", local.cloudtrail_member_accounts)
"projection.region.type" = "enum"
"projection.region.values" = join(",", local.cloudtrail_regions)
"projection.year.type" = "integer"
"projection.year.range" = "2024,2030"
"projection.month.type" = "integer"
"projection.month.range" = "1,12"
"projection.month.digits" = "2"
"projection.day.type" = "integer"
"projection.day.range" = "1,31"
"projection.day.digits" = "2"
"storage.location.template" = local.cloudtrail_partition_template
}
Enums for accounts and regions (finite, stable sets), integer ranges for year/month/day (bounded). Pin the account list as a Terraform local, not a data source — keeping the projection enum static means queries don’t re-evaluate every account lookup on every run. New day tomorrow? Already covered by the year range. New account next quarter? Add it to the enum list — one line of Terraform.
Two gotchas worth flagging for anyone building the same thing.
First, Control Tower’s S3 layout repeats the organization ID. The actual key prefix is
<org-id>/AWSLogs/<org-id>/<account-id>/.... If you follow the AWS-published DDL assuming the
standard AWSLogs/<account-id>/... layout, your storage.location.template points at an empty
prefix and every query returns zero rows. That one cost me a cycle.
Second, the canonical CloudTrail DDL that AWS publishes includes two fields — ec2roledelivery
and webidfederationdata — whose shape varies across event types (sometimes a map, sometimes
a struct). The CloudTrail SerDe is name-based and silently skips omitted columns, so leaving
them out of the column list is both safe and necessary. Including them triggers HIVE_BAD_DATA
on real traffic with no useful error.
The work was tedious. The payoff was immediate.
The real RCA, in CloudTrail
Once Athena was live, I pulled the timeline for a specific known failure: instance
i-0f3066deda420ab46, 2026-01-30 10:31:07Z, us-west-1, ASG
actions-runner-20250305195042633700000003-Y20MOj. Here’s what CloudTrail showed, to the second:
| Time (UTC) | Actor | Event |
|---|---|---|
| 10:26:43 | runner | SetInstanceProtection(protect=false) — postrun, job 2 finished cleanly |
| 10:26:43 → 10:31:04 | — | instance idle ~4.5 minutes |
| 10:31:04 | ASG | scale-in fires → instance enters Terminating:Wait, deregistration Lambda invoked |
| 10:31:05 | ASG | RunInstances — replacement instance launching |
| 10:31:06 | deregistration Lambda | CreateLogStream |
| 10:31:07 | runner | SetInstanceProtection(protect=true) → FAILED (prerun hook) |
| 10:31:09 | runner | SetInstanceProtection(protect=false) → OK (postrun, after prerun’s exit 1) |
| 10:31:11 | deregistration Lambda | DeleteSecret for the registration token |
| 10:31:15 | deregistration Lambda | SendCommand (SSM systemctl stop actions-runner) |
| 10:31:17 | deregistration Lambda | CompleteLifecycleAction |
| 10:31:18 | ASG | TerminateInstances |
This is not a warm-pool resume race. It’s a scale-in race.
At 10:26:43, the runner finished a job cleanly, unprotected itself, and went idle. Four and a half
minutes later, the ASG’s scale-in policy decided there were too many idle runners and picked this
one for termination. The instance entered Terminating:Wait, which fired the deregistration
lifecycle hook, which invoked a Lambda whose job was to SSM the instance with systemctl stop actions-runner so the runner would deregister from GitHub before the VM went away.
That Lambda took eleven seconds to actually issue the SSM command (from scale-in at 10:31:04 to
SendCommand at 10:31:15). During those eleven seconds, the actions-runner process was still alive
and still polling GitHub’s dispatch API. At 10:31:07 — three seconds into the
Terminating:Wait state — GitHub handed it a queued job. The prerun hook fired,
called SetInstanceProtection(protect=true), and AWS rejected it because the instance was no
longer in InService.
Two seconds later, the postrun hook ran SetInstanceProtection(protect=false) and AWS accepted
it. That’s the asymmetry that made the whole thing look weirder than it was: you cannot protect
a terminating instance, but you can unprotect it. AWS permits clearing protection on a terminating
instance because it treats “clear protection” as idempotent — callers often want to unprotect
during teardown, and erroring on them would be hostile. The API is asymmetric by design.
The “non-existent instance ID” framing from the original ticket was a timing artifact. The instance
was real at the moment of the failure. Seconds later it was terminated. An hour later it aged out
of describe-instances. By the time anyone investigated, all that remained was a stale ID in the
error message and no way to tell the story of what actually happened — unless you could query
CloudTrail.
There’s one more subtlety worth noting. CloudTrail records this same failure as
InvalidParameterValueException: "An unknown error occurred", not the
ValidationError: "not in InService or EnteringStandby or Standby" that the SDK surfaces to the
caller. If you grepped your audit logs for the SDK-level error text, you’d find nothing. The
CloudTrail-side error code is a generic AWS umbrella, and the message is actively misleading. You
have to know the event name (SetInstanceProtection) and filter on errorcode IS NOT NULL to find
the failures at all. That mismatch is part of why the first RCA went sideways — the investigator
never saw the authoritative error, only the SDK-transformed version on the runner instance.
The fix: make the race survivable
The obvious next question is how to close the race. The honest answer is: we can’t, not cleanly. The options and why each fails:
Shrink the SSM round-trip. The eleven-second window between Terminating:Wait and the
systemctl stop command reaching the instance is the race. If we could cut it to zero, the race
goes away. But SSM’s latency is not in our control. The eleven seconds isn’t a bug; it’s the
speed of the control plane. Moving systemctl stop onto the instance itself — a local daemon that
watches lifecycle state and kills the runner the instant it flips — would shrink the window to a
second or two. But we still have a window. And we’d trade a known, testable external control path
(Lambda → SSM) for a bespoke instance-local daemon we’d have to maintain.
Use GitHub’s --ephemeral runner mode. This is GitHub’s recommended solution for autoscaling:
each runner processes one job and exits. No idle runners, no scale-in race. But it conflicts with
our product requirements. Our CI runs distributed compilation jobs that reuse local build
caches across runs. Ephemeral runners would throw the cache away every job and tank CI times.
We’ve already chosen long-lived runners for that reason.
Prevent GitHub from dispatching jobs to Terminating:Wait instances. The actions-runner
process is closed-source to us. We can’t intercept its dispatch loop. We’d have to proxy GitHub
itself, which isn’t realistic.
So we stopped trying to close the race and asked a different question: what if we made the race harmless?
The race happens. A job lands on a Terminating:Wait instance. The prerun hook fails. Right now
that failure aborts the job. But nothing about the VM actually prevents the job from running —
the filesystem is there, the network works, the runner binary is running. The only thing standing
between “this job succeeds” and “this job fails” is the prerun hook treating a protection error
as fatal.
If we make the prerun tolerate Terminating:Wait, the job proceeds. Then we need systemd to let
the in-flight job finish before the runner gets killed, which means a much longer
TimeoutStopSec and KillMode=process so the Worker survives. Then we need the lifecycle hook
to stay open long enough for the job to finish, which means either a very long
heartbeat_timeout or an explicit heartbeater. Then we need ExecStopPost to complete the
lifecycle hook after the runner exits so the instance can terminate cleanly.
That’s the design. It accepts that a job can land on a terminating instance and makes that path successful.
Four PRs
The implementation spanned two repositories. I’ll describe what changed rather than walking through every diff.
infrahouse/terraform-aws-actions-runner#92 — the Terraform module side.
- The deregistration lifecycle hook’s
heartbeat_timeoutis now 30 minutes (down from the 1-hour default), with an instance-local heartbeater extending it as needed for longer jobs. - The deregistration Lambda no longer waits for SSM completion. It fires
systemctl stop actions-runnerand returns. The instance’s ownExecStopPosthandler now owns completing the lifecycle action. Lambda invocation went from ~10s to ~1s. - Registration-token cleanup moved out of the Lambda and into Puppet, co-located with the code that actually consumes the token. Cleaner lifetime, fewer moving parts.
- IAM additions:
RecordLifecycleActionHeartbeatandCompleteLifecycleActionon the instance profile so the heartbeater andExecStopPostcan do their jobs.DeleteSecretscoped narrowly to the instance’s own token secret. - The deregistration hook name is now injected as a custom Puppet fact via the cloud-init external-facts mechanism, so the scripts on the instance know which hook to complete.
infrahouse/puppet-code#265,
#268,
#269 — the instance-side changes,
promoted through development → sandbox → global in three PRs per the puppet-code convention.
The prerun hook now tolerates Terminating:Wait and Terminating:Proceed:
if ! /usr/local/bin/ih-aws autoscaling scale-in enable-protection 2>/tmp/prerun_err; then
instance_id=$(ec2metadata --instance-id)
state=$(aws autoscaling describe-auto-scaling-instances \
--instance-ids "$instance_id" \
--query 'AutoScalingInstances[0].LifecycleState' --output text 2>/dev/null || echo "")
case "$state" in
Terminating:Wait|Terminating:Proceed)
echo "prerun: instance is in $state — skipping protect, job will proceed" >&2
;;
*)
cat /tmp/prerun_err >&2
exit 1
;;
esac
fi
Real errors still fail. Only the “we’re already terminating” path gets tolerated.
A new ExecStopPost script completes the deregistration lifecycle hook after the runner exits:
hook_name="${DEREGISTRATION_HOOK_NAME:-}"
[[ -z "$hook_name" ]] && exit 0 # old-Terraform ASG — old Lambda handles it
state=$(aws autoscaling describe-auto-scaling-instances \
--instance-ids "$(ec2metadata --instance-id)" \
--query 'AutoScalingInstances[0].LifecycleState' --output text 2>/dev/null || echo "")
case "$state" in
Terminating:Wait|Terminating:Proceed)
ih-aws autoscaling complete --hook "$hook_name" --result CONTINUE
;;
esac
A new systemd timer unit wakes up every 10 minutes and, if the instance is in Terminating:Wait,
calls RecordLifecycleActionHeartbeat to push out the hook’s expiry. This keeps arbitrarily long
jobs alive through the lifecycle hook’s timeout.
The three silent bugs we fixed along the way
While I was in the systemd unit I found three real bugs that were silently biting every clean runner stop, not just during scale-in. They’d been in the unit file since the runner was first deployed.
The old unit had KillMode=control-group (systemd’s default). When systemd stopped the service,
it SIGKILLed every process in the runner’s cgroup — including the Worker process executing the
actual CI job. Any systemctl stop actions-runner, for any reason, killed in-flight jobs. The fix
is KillMode=process, which sends the stop signal only to the main process and lets children
finish. This is the configuration GitHub’s own install scripts use. We’d drifted from it somewhere
along the way.
The old unit had TimeoutStopSec=90s (systemd’s default). Real CI jobs, especially Terraform
plans and applies, routinely take longer than 90 seconds. When the 90s expired, systemd escalated
to SIGKILL regardless of KillMode. The fix is TimeoutStopSec=21600 (6 hours), which covers
any realistic Terraform apply in our CI. Jobs that genuinely exceed 6 hours are a separate
problem; the new value is a reasonable ceiling, not a license for unbounded jobs.
The old unit called the runner tarball’s run.sh directly. The runner tarball also ships
runsvc.sh, which wraps run.sh with trap 'kill -INT $PID' TERM INT — translating SIGTERM
into the graceful-shutdown signal the runner actually honors. Without the trap, SIGTERM from
systemd went straight to run.sh, which doesn’t handle it cleanly. The fix is to exec runsvc.sh
instead. This is also what GitHub’s install scripts do.
None of these were the bug I was chasing. All of them were real. They all got fixed.
Confirmation
The fix went to sandbox first, baked for a week, then promoted to production. On April 19, I queried CloudTrail to find a production instance that had hit the race since the fix deployed:
SELECT eventtime, awsregion, errorcode, errormessage,
useridentity.arn AS caller_arn, requestparameters
FROM cloudtrail_logs.events
WHERE year = '2026' AND month = '04' AND day = '19'
AND eventname = 'SetInstanceProtection'
AND errorcode IS NOT NULL
ORDER BY eventtime;
One result, instance i-0286686bd902e89e6, 21:12:29 UTC. The caller ARN identified the runner.
Cross-referencing CloudWatch Insights for the same instance ID turned up the deregistration
log line from the Lambda: “Instance i-0286686bd902e89e6 is terminated. Will deregister the
runner ip-10-1-1-225.” Then a short shell loop against the GitHub API across every repo in
the org found the affected job.
The job’s conclusion: success. The log includes the new prerun line:
prerun: instance is in Terminating:Wait — skipping protect, job will proceed
Job completed. Postrun ran. Runner exited. ExecStopPost completed the lifecycle hook. Instance
terminated cleanly. Nobody was paged. Nobody opened Slack to ask why their PR was red.
What I’d tell another infra team in this spot
Three things.
If you use Control Tower, set up Athena on the log-archive CloudTrail bucket before you need it. It’s a day of work. The day you need it you’ll need it very badly. The point of aggregated audit logs is that they’re queryable. Without Athena you have a write-only audit trail, which is the worst kind.
Intermittent failures with cheap workarounds compound. This bug hit once every day or two. Rerun the job, move on. Two and a half months of that is an enormous amount of senior-engineer attention, distributed so thinly across the team that nobody notices the total bill. The value of fixing it comes from the context switches eliminated, not the minutes saved per failure.
AI-assisted RCAs are only as good as the data you feed them. The first RCA on this bug was generated by an AI assistant with access to the error message and the instance IDs, nothing else. It produced a plausible, internally consistent, specific, wrong answer. The hypothesis it landed on — warm-pool resume race — was a hypothesis the available evidence couldn’t distinguish from the correct one. The remedy is to give the AI (and yourself) access to authoritative data. An RCA over CloudTrail would have landed the correct answer in minutes. An RCA over error messages and the GitHub issue ran dry because there wasn’t enough signal in the input.
If you’re running self-hosted GitHub Actions runners on AWS and this post sounded familiar, I’d like to hear about your setup. The InfraHouse actions-runner module is open source and battle-tested against exactly the kind of workload that produces bugs like this. Book a chat.