The startup I work with builds AI agents for enterprises. I handle the infrastructure. The founders and their engineers build the product.
Early on, the team started talking to a well-known public company — a unicorn. The conversation was promising: “Your solution looks interesting. Prove it works and we can give you some business.” The engineers delivered a successful proof of concept. Then the unicorn asked:
“Are you guys secure at all? Do you have any certifications?”
The founders came to me with that question. My answer was: to the best of my knowledge, what I’ve built is secure. But don’t take my word for it. Let’s hire auditors and get certified. That way we make the customer happy — they asked, we deliver. And if there’s anything wrong with the infrastructure, whether I missed something or made a mistake, I’d rather hear it from auditors than from hackers.
So we signed a contract with an audit firm. We had to choose where to start — SOC 2 or ISO 27001. We chose ISO because it’s more internationally recognized, and our potential customers weren’t just in the US.
This is the story of what that process looked like when your infrastructure is already built on Terraform and AWS — and what I learned along the way.
Why Startups Should Care About Compliance
If you sell to enterprises, certifications aren’t a nice-to-have. Your customers’ legal and procurement teams require them. You can’t close deals without them.
And getting the certificate is only the beginning. Clients will send you vendor assessment forms regardless of whether you present a certificate. Those forms usually repeat the ISO controls as direct questions, and you need to have answers ready.
Even with an ISO 27001 certificate in hand, the forms still come. Two reasons. First, many certifications are shallow. Let’s be honest — plenty of companies convince auditors they’re compliant when the reality is different. “ISO in 6 weeks!” — really? Clients know this. Second, the assessment forms increase your contractual liability. You’re answering direct questions in writing. Sometimes those answers creep into contracts. That’s a legal risk if your actual controls don’t match what you wrote down.
So you need to get certified, and you need to implement it properly.
Why Early
The common startup wisdom is: focus on the product first, deal with security later. But be honest with yourself — when exactly is “later”? There will never be a calm period where you can afford to slow down and sort out access control, change management, and environment separation. You need to deliver, constantly.
Here’s how it actually plays out. Security and compliance seem insignificant at first. Then a real prospect is ready to close — and when they ask about certifications, you’re 13 months behind.
There’s no other option but to build fast, secure, and compliant from the start.
We chose ISO 27001 because it goes beyond a checklist of controls. It’s a framework for how a company thinks about information security — connecting technical controls with organizational processes like access management, incident response, vendor evaluation, and change control. And it requires you to prove those controls actually work.
Infrastructure decisions made in the first months of a startup’s life are the hardest to change later. IAM design, encryption strategy, account structure, deployment pipelines — these become load-bearing walls. By embedding ISO principles into Terraform modules and AWS architecture from the beginning, we avoided the painful retrofit that happens when companies bolt on compliance years later.
The Architecture

I’ll walk through the key pieces. If you’ve worked with AWS and Terraform, this will be concrete. If you haven’t, the point is that every security control exists as code — versioned, reviewed, and automatically enforced.
Multi-Account Isolation
We use AWS Control Tower with dedicated accounts for production, development, sandbox, and customer workloads. Each account has its own IAM boundaries, logging pipelines, and monitoring. A mistake in development can’t cascade into production because they’re not in the same account — they’re not even in the same IAM boundary.
This satisfies ISO 27001’s requirements for environment separation (A.12 and A.13), but it’s also just good engineering. You want isolation regardless of compliance.
Access Control
Identity is centralized through AWS IAM Identity Center (SSO). Every user authenticates with MFA. There are no static IAM keys anywhere — engineers assume temporary roles through SSO sessions, and every role follows least privilege, defined in Terraform.
No one can approve their own deployment. Production access requires peer review. If one person’s credentials are compromised, the damage is scoped to what that role can touch.
Everything about who has access to what is in .tf files. When access is granted or revoked, it’s
a pull request with a timestamp, a reviewer, and a description of what changed. That history doesn’t
need to be reconstructed for an auditor — it already exists in Git.
I wrote about how this works at the GitHub organization level in One Repo to Rule Them All. The same principle applies to AWS: permissions are code, and code has history.
CI/CD Without Secrets
Deployments use GitHub Actions with OIDC-based federated roles. No AWS credentials are stored in GitHub — the runner assumes a temporary role scoped to exactly what that workflow needs.
Code never reaches production directly from a developer’s laptop. Every change goes through a pull request, gets a Terraform plan comment, gets reviewed, and merges before anything touches AWS. The pipeline serves as change control.
Encryption
Encryption is baked into every layer. All data in transit uses TLS 1.2+. For data at rest, we applied a deliberate key management strategy:
CloudTrail logs get customer-managed KMS keys for full audit visibility. Databases use CMKs with rotation. Application logs in CloudWatch use AWS-managed keys per CIS Benchmark v3 guidance. S3 buckets follow service-level defaults with CMKs applied where customer or compliance requirements demand explicit key ownership.
Every encryption policy and key configuration is defined in Terraform. When an auditor asks “how do you manage encryption?”, you point them at a file in a Git repository.
Centralized Logging and Detection
CloudTrail, AWS Config, Security Hub, and GuardDuty are centralized across all accounts. Security Hub benchmarks give us real-time posture metrics. Alerts flow into Slack and our issue tracker, closing the loop between detection and response.
Logging is part of the Terraform that provisions every account. You don’t get an AWS account without it.
Monitoring That Can’t Fall Behind
Vanta flagged that we were missing alarms — no ALB monitoring, no Lambda error rate tracking, no RDS metrics. So we added them. Problem solved, until the infrastructure kept growing. New load balancers, new Lambdas, new databases got created — and the alarms didn’t follow. Monitoring fell behind because it was a separate step from provisioning.
The fix was to make monitoring a property of the module itself. If a Terraform module creates a
Lambda, it must also create the alarms to monitor it. That’s how the
lambda-monitored module was born.
When we create a load balancer, the alarms come with it. A resource can’t exist without its
monitoring — they’re the same terraform apply.
That kept compliance consistent without anyone having to remember to add alarms after the fact.
Vulnerability Management

I think about vulnerability management the same way I think about incident response. A vulnerability deployed to production is an incident. So the pipeline follows the same structure: prevention, detection, notification, remediation.
Prevention. We scan at the CI stage, before anything reaches production. OSV-Scanner checks dependencies in lock files. Trivy scans Docker images to cover packages baked into the containers. If a vulnerability is known at build time, the code doesn’t ship.
Detection. You can commit clean code today, and tomorrow a dependency becomes vulnerable. We need to catch that. GitHub Dependabot continuously scans repositories and opens pull requests when patches are available. AWS Inspector performs a similar function on the infrastructure side — scanning Docker images in ECR and EBS volumes for newly discovered CVEs.
Notification. Vanta aggregates vulnerability information from all sources. When something is discovered, it creates a finding. A Lambda function pulls findings from Vanta, double-checks them against AWS Inspector and GitHub Dependabot, identifies the owner, and creates a Linear ticket with an SLA. The same Lambda works in the other direction too — if a vulnerability has been resolved but the ticket is still open, it closes it. The Lambda also generates a dashboard with vulnerabilities, tickets, SLAs, and owners.
Remediation. Fixing vulnerabilities is part of the regular engineering workflow — tickets with deadlines, tracked like any other work. One less obvious angle: a Docker image can’t be vulnerable if it’s been deleted. Our ECR module implements a lifecycle policy that deletes old images aggressively while protecting deployed images and rollback candidates.
Choosing the Right Metric
ISO 27001 requires you to define security objectives and measure progress toward them.
The traditional metric is “number of security incidents per quarter.” I’ve seen what this does to a team. At a previous company, a similar metric — number of reliability incidents per quarter — yielded terrible results. People spent their energy arguing “no, it’s not an incident” and “no, it’s not our incident” instead of fixing problems. The metric incentivized the wrong behavior: silence and finger-pointing, not improvement.
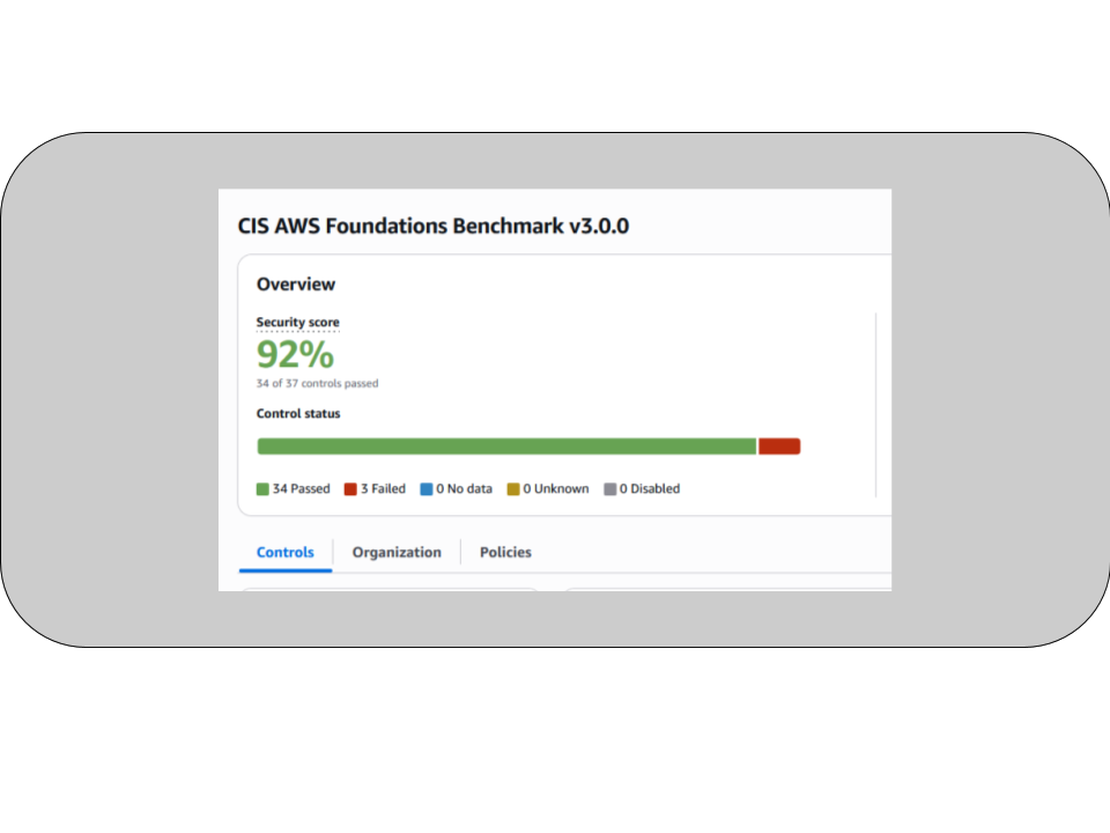
We chose a different approach. Instead of counting incidents, we measured security posture directly. We adopted the CIS AWS Foundations Benchmark v3.0.0 inside Security Hub and treated its compliance percentage as our Security Score.
Security Hub continuously evaluates every AWS account against dozens of controls — encryption, IAM scope, logging configuration, network exposure. Each failed control is a specific, actionable issue. The score goes up when you fix things. It goes down when you introduce risk.
Our target was 70%. We hit 92% and kept climbing.
The score made security work visible. When an engineer fixed a misconfigured S3 bucket, the number went up. When someone introduced a new resource without proper encryption, it went down. The whole team could see where we stood, and fixing things felt productive instead of like compliance busywork.
Right incentives work.
What the Audit Actually Looked Like
By the time the auditors showed up, most of the work was already done.
The external audit had two stages: Stage 1 reviewed documentation, scope, and risk assessment. Stage 2 verified control implementation through live evidence and interviews.
We didn’t grant auditors direct access to AWS or GitHub. Instead, we walked them through live infrastructure in screen-sharing sessions. They saw real Terraform definitions showing encryption and IAM boundaries. They saw GitHub pull requests demonstrating peer reviews and change approvals. They saw Security Hub dashboards with live CIS benchmark scores. They saw Inspector and Trivy reports confirming continuous vulnerability scanning.
The evidence was the actual system, running in production, doing what it does every day.
The auditors’ feedback was that the compliance followed naturally from how the system was engineered. That was the goal.
We passed both stages. Certificate issued.
Evidence Generation
Because every control was defined in code, generating audit evidence was straightforward.
Who has access to what? It’s in the Terraform files. When was access revoked? It’s in the Git history. Does every repository have vulnerability scanning? It’s enforced centrally — repositories can’t opt out because the workflow is managed by the same system that creates the repo. Who owns each service? There’s a metadata file in every repository.
The compliance evidence came from the same infrastructure we’d use regardless of whether we were getting certified. We just made sure it was managed as code from the start.
The first time the auditor asked “can you show me your access control process?”, we showed them a pull request.
What I Learned
People ask what I’d do differently. Honestly, most of it I’d do the same way. I didn’t have the knowledge to do it differently at the time — the learnings came from going through the process.
The good news is that those learnings are now embedded in the Terraform modules. ECR lifecycle management, ALB and ECS alarms, Lambda monitoring, encryption defaults — all the things we had to figure out during the ISO journey are now built into the modules themselves. If I set up a second company’s infrastructure tomorrow, the ISO features come free because the modules already have them.
The one tool I’d buy on day one is Vanta. We used it for document management, evidence linking, and review workflows. It gave auditors clear traceability from written policy to implemented control. The integration effort was minimal and the audit payoff was significant.
What I would not buy again: Snyk and SentinelOne.
Snyk was too rigid. It either blocked a PR entirely or let vulnerabilities slide. There was no middle ground — no way to file an exception and say “we accept this risk for now, here’s the SLA.” If you block the PR, you stop development even when the change is an emergency fix unrelated to the vulnerable dependency. If you don’t block it, developers merge and forget. I wrote about this in more detail in the OSV-Scanner post.
SentinelOne generated around 30,000 notifications per day. It flagged routine operations like package installations during server provisioning as threats. When your monitoring tool can’t distinguish between Puppet installing nginx and an actual attack, it’s creating work instead of reducing risk.
Wrapping Up
ISO 27001 certification is achievable at startup speed. You don’t need a dedicated compliance team or a six-month pause on feature work. You need infrastructure as code so that evidence generates itself, a metric that reflects actual security posture, and documentation written early while your system is still small enough to describe accurately.
When your controls are real and your infrastructure matches what you claim, the vendor assessments become easy — you’re describing what actually exists.
If you’re a startup founder thinking about this, I’m happy to share more detail. Book a conversation or check out how we manage 100+ repos from a single Terraform state.