Nobody Wants to Create a New Repo
- Oleksandr Kuzminskyi
- March 23, 2026
Table of Contents
I run infrastructure for a startup. Over the past two years I’ve built a system that manages the company’s entire GitHub organization — over 100 repositories, their permissions, CI/CD pipelines, AWS environments, and security policies — from a single source of truth.
This post isn’t about how it works. I wrote a technical deep-dive for that. This post is about what it means for the business — the problems it solves that have nothing to do with Terraform and everything to do with running a startup that doesn’t break as it grows.
If you’re a startup CTO or founder, you’ve probably picked one of two paths for your infrastructure.
The first is ClickOps. You create repos through the GitHub UI. You configure CI/CD by hand. You copy-paste AWS credentials into GitHub secrets and hope nobody commits them to a public repo. Permissions are assigned by clicking buttons. When someone leaves the company, you click through every repo trying to remember what they had access to. It works fine at five repos. It’s painful at twenty. At fifty, it’s a full-time job that nobody signed up for.
The second is hiring a DevOps engineer. That’s $180–220K fully loaded, a three-month ramp before they’re productive, and now you have a single point of failure building custom tooling that only they understand. If they leave, you’re back to ClickOps — except now you’re also maintaining whatever they built.
There’s a third option: infrastructure that works like a product. You describe what you want, and the system builds it — the repo, the environments, the permissions, the pipelines, the security scanning, everything. That’s what we run. Here are five things it changed about how the company operates.
Someone Quits on Friday
An employee left the company. Good person, no drama — they just moved on. The founder needed to revoke their access across the entire organization. Every GitHub repo, every AWS role, every CI/CD secret.
Without our system, that’s an afternoon of clicking. Open each repo’s settings. Check collaborators. Check team memberships. Check deploy keys. Check GitHub Actions secrets that might contain shared credentials. Hope you didn’t miss anything. You’re never fully confident it’s done. Six months later, during a security review, you discover they still had push access to three repos you forgot about.
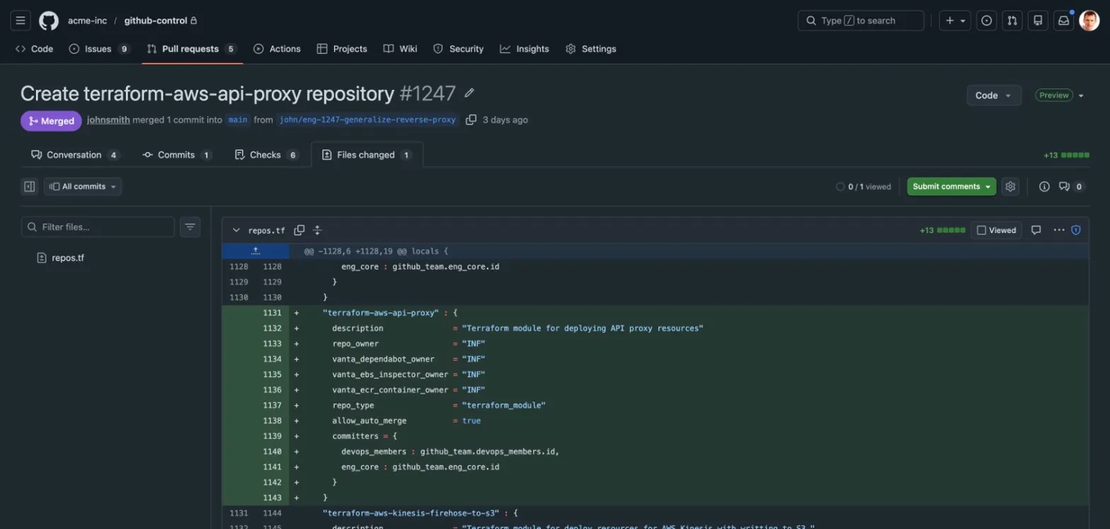
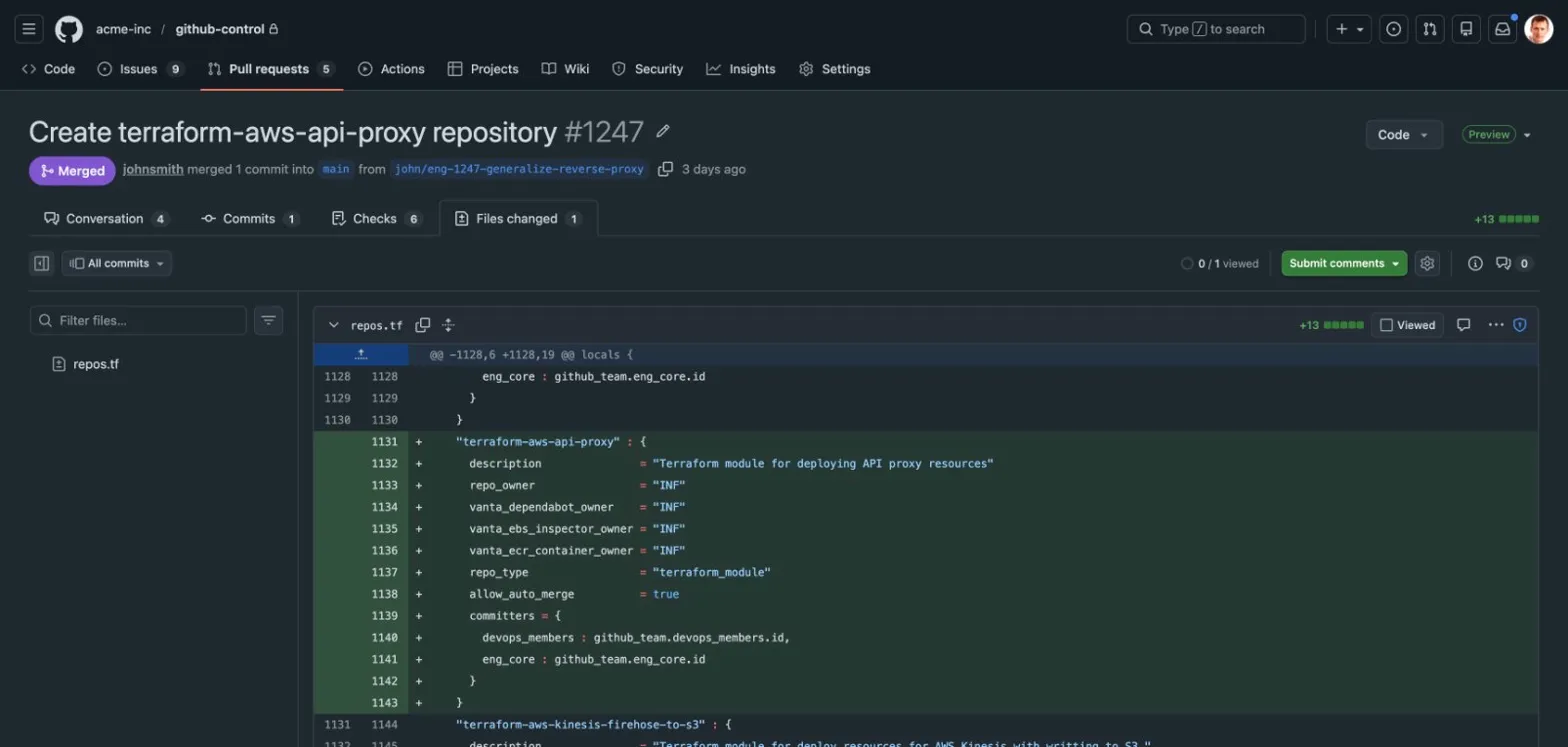
Here’s what actually happened: the founder searched the codebase for the employee’s username. Every reference appeared in configuration files — team memberships, repo permissions, code ownership rules. He removed them, opened a pull request, and merged it. One commit. Access revoked across the entire organization. The PR shows exactly what changed, who approved it, and when.
That’s not a DevOps story. That’s a “can you prove to an auditor exactly when you revoked this person’s access?” story. The answer is a link to a pull request with a timestamp and a reviewer’s approval.
The Engineer Who Couldn’t Ship
We had a junior engineer — smart, curious, motivated — who wanted to launch a new service. He tried to do it through the AWS console. ClickOps. Target groups, task definitions, security groups, IAM roles, load balancer listeners, health checks. He spent days on it. Got nowhere.
The problem wasn’t the engineer. The problem was that launching a service required tribal knowledge that nobody had written down. Which VPC? Which subnets? What IAM permissions does the task need? How do you wire up the load balancer? How do you configure health checks so ECS doesn’t kill your container on startup? Every answer was “ask the person who did it last time” — and that person was me.
Then I built the deployment module. Same engineer launched the service in an afternoon. Then he launched four more. Two environments each — sandbox and production. Identical configurations. Reproducible deployments. When something broke in sandbox, he could fix it with confidence that the same fix would work in production, because both environments came from the same definition.
The question for your startup is: how many engineer-days does your team burn on infrastructure that should be a configuration change? How many services aren’t getting launched because the path from “code is ready” to “running in production” requires a senior engineer to hold someone’s hand through the AWS console?
100 Repos and Nobody Asked
Here’s something I didn’t expect.
Nobody at the company has ever argued about monoliths. There’s no “monolith vs. microservices” debate. No architecture review board. No mandate from leadership about how to structure code. The engineering team just… creates new repositories when they need them. Over 100 so far. I never asked them to. I never even mentioned the word “monolith.”
I think I know why. When creating a new repository means two hours of manual setup — permissions, branch protection, CI/CD, secrets, code ownership, state buckets — you don’t do it unless you absolutely have to. So the next feature goes into the existing repo. Then the next one. Then the next one. Six months later you have a monolith, not because anyone designed one, but because the alternative was too expensive.
When creating a new repository is a fifteen-line configuration change that takes ten minutes to provision — with CI/CD, permissions, environments, and security scanning included automatically — the calculus flips. The right thing becomes the easy thing. Engineers create new repos because it’s the path of least resistance, not because someone told them to.
The cost of unwinding a monolith is months of work, frozen features, and team friction. The cost of preventing one is making repo creation frictionless from the start.
The New Engineer on Monday
Every repository in the organization has the same coding standards, the same CI/CD workflows, the same security scanning, the same dependency update configuration, and the same AI coding assistant instructions. Not because someone wrote a wiki page about it. Because the files are managed centrally and deployed to every repo automatically.
When a new engineer joins the company and clones any repository, the standards are already there. They don’t need to find a Confluence page called “Engineering Standards” that three people read when it was published and nobody has updated since. They don’t need to ask “how do we do things here?” in Slack and wait for someone to respond with a link to an outdated Google Doc.
The AI coding assistant is a good example. Every repo has a configuration file that tells the assistant how the company writes code — formatting rules, testing standards, security requirements, naming conventions. Update that file in one place, apply the change, and every repo in the organization picks it up. Every engineer’s AI assistant enforces the same standards, whether they joined yesterday or two years ago.
This is the kind of consistency you can’t get by writing documentation and hoping people read it. The standards aren’t documented — they’re deployed.
The Audit You Haven’t Had Yet
At some point, if your startup is successful, an enterprise customer is going to ask for your SOC 2 report. Or your ISO 27001 certification. Or just a security questionnaire that asks: “Describe your access control process. How do you ensure that terminated employees lose access promptly? How do you enforce consistent security policies across your codebase?”
If your infrastructure is ClickOps, answering those questions is a multi-week scramble. You piece together screenshots, Slack messages, and vague recollections of when you changed someone’s permissions. You write policies that describe how things should work, hoping nobody checks whether they actually do.
If your infrastructure is managed as code, the evidence already exists. Who has access to what? It’s in the configuration files. When was access revoked? It’s in the Git history — with a timestamp, a reviewer, and a description of what changed. Does every repo have vulnerability scanning? It’s enforced automatically — repos can’t opt out because the workflow is managed centrally and overwritten on every apply. Who owns each service? There’s a metadata file in every repo with the owning team, maintained by the same system that manages everything else.
You don’t build compliance tooling. You get it as a side effect of managing your infrastructure properly. The first time a customer asks “can you show me your access control process?”, you show them a pull request.
What This Actually Is
This is a system where adding a new service takes fifteen lines of configuration and ten minutes. Where offboarding is one pull request. Where new engineers are productive on day one. Where monoliths don’t happen because creating repositories is free. Where compliance evidence generates itself.
I built this for a real startup. It runs in production today, managing over 100 repositories across multiple AWS accounts. It’s not a demo. It’s not a proof of concept. It’s what the engineering team uses every day to ship.
If you’re a startup CTO spending engineer time on infrastructure plumbing — or worse, not doing it and accumulating technical debt you’ll pay for later — I’d like to hear what your version of this problem looks like.
Book a conversation — or read the technical deep-dive to see how it works under the hood.